The Ultimate LLM Providers Shopping Guide
How to run your agentic workflow cheaply

What Is the Most Cost-Effective Way to Run a Large Language Model (LLM)?
When leveraging Large Language Models, you face a key decision: where should you run them? Options have multiplied, each with its own trade-offs. Should you:
- Purchase dedicated hardware to run an open-source LLM locally?
- Use a cloud service like OpenAI or Google Gemini, or pay for inference on a platform that hosts open‑source LLMs such as Groq or DeepInfra?
- Rent raw GPU power from a cloud provider like Modal to host an open‑source model yourself?
I’ve explored all three paths, and here are my findings.
Running Open‑Source LLMs Directly on Your Machine — or Why Apple Stock Is Going to Explode
If you want to run an LLM locally, you first need to pick a worthwhile open‑source model.
You want the smartest open‑source model you can run with the lowest hardware requirements.
To do that, look at leaderboards like:
I prefer Artificial Analysis because it computes an “intelligence index,” a composite of multiple renowned benchmarks for each model.
As of now, the new gpt-oss-120B appears to be the cheapest to run on cloud providers while maintaining a strong score (61), placing it second in intelligence. If it’s cheaper to run in the cloud, it’s likely less computationally demanding—and the same will hold on your hardware too.
Now, gpt-oss-120B needs high‑end hardware like an NVIDIA A100 or H100 with 80 GB of VRAM (memory dedicated to the GPU).
The interesting part is that Apple’s architecture blends VRAM and RAM and elude this reliance on the GPU only.
Apple’s Secret Economic Moat: Unified Memory Architecture (UMA)
On traditional PCs, the CPU has its own memory (RAM), and the GPU has its own separate, faster memory (VRAM). When running an LLM, data must constantly be copied back and forth between these two separate memory pools, creating a significant bottleneck that slows everything down.
Apple’s M‑series chips, such as the M4 Max, use a different approach.
Shared Memory Pool: With UMA, the CPU, GPU, and Neural Engine (NPU) share a single, large pool of high‑speed memory. Your local RAM is this unified pool.
No Copying Needed: Because all components are using the same memory, there’s no need to duplicate or transfer huge amounts of data. The GPU can directly access the model data the CPU is using with minimal delay. This dramatically increases efficiency and speed.
That’s why some people have had pretty decent results (40 tokens/sec) running gpt-oss-120B on an M4 Max: https://www.reddit.com/r/LocalLLM/comments/1mix4yp/getting_40_tokenssec_with_latest_openai_120b/
For comparison, ChatGPT online delivers around 100 tokens/sec. That said, a 128 GB RAM MacBook Pro M4 Max currently sells for $6,399—not cheap—but for a company running LLMs locally and paying only for electricity, it can make sense. Apple may be behind in the LLM revolution, but it owns the hardware to make it scalable and affordable. Waiting for Wall Street to realize it (this is not financial advice).
I Tested GPT-OSS-20B on My MacBook Air M2 (24 GB)
Of course, my MacBook Air couldn’t run the largest GPT‑OSS model, but I did run the 20B version and got ~20 tokens/sec, which was okay.
If you want to try it, here’s the simplest way:
- Download LM Studio from here
- Open the app and click to download the GPT‑OSS‑20B model

- Click on the “Start chat” button
- You will see the chat interface
- Ask a question. I asked, “How to clean jewelry the right way?” and here is the token generation rate:
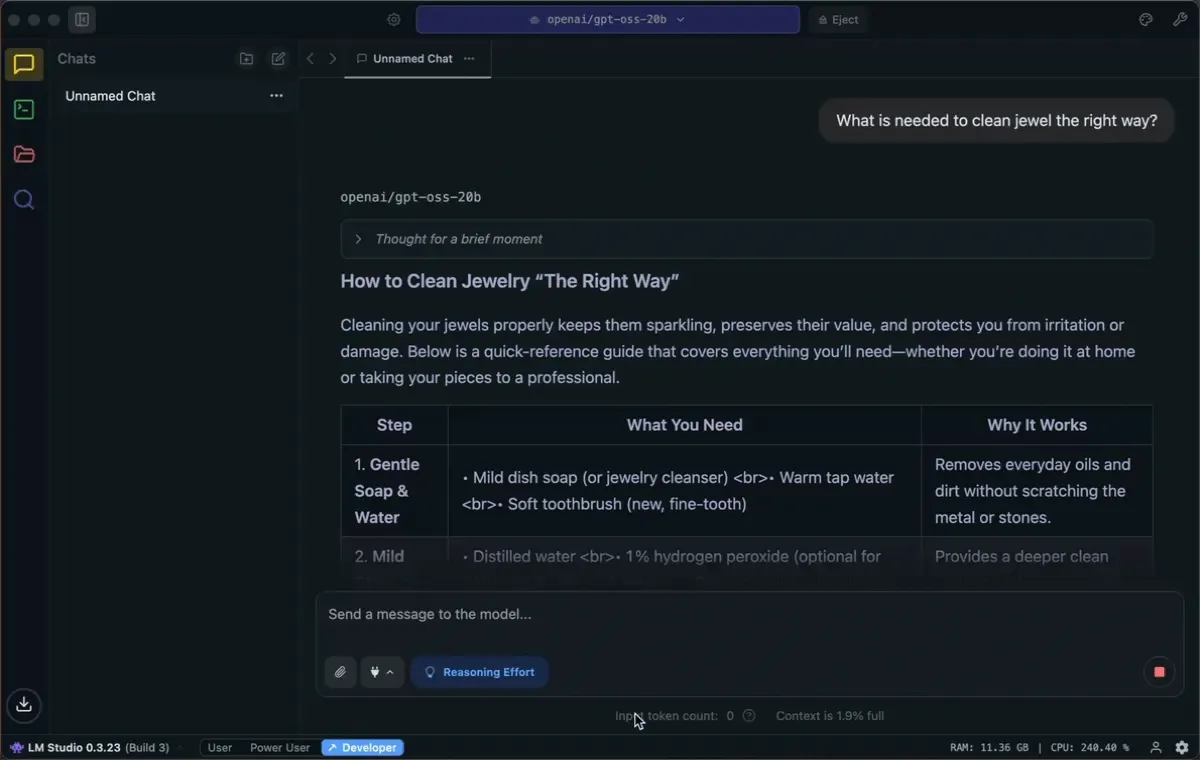
- You can see the tokens‑per‑second stats at the bottom:

⚠️ Quick Warning
Just a quick note: LM Studio or open‑webui are interesting for playing with a model, but they do not replace a chat interface like ChatGPT, Claude, or Gemini. LM Studio and open‑webui don’t provide the same agentic capabilities out-of-the-box (web search, web scraping, document parsing, etc.) that these proprietary platforms offer to optimize model behavior. You can try to configure those capabilities in open‑webui, but you’ll likely not reach the same level of quality and performance as those online platforms.
Running Open‑Source LLMs on Inference Providers
Artificial Analysis can help you find the best inference providers. Basically, you want to sort models by intelligence index and compute the price per intelligence‑index point to find the best deal, then check which providers offer those models. I computed this and summarized it in the table below:
| Model | Artificial Analysis Intelligence Index | Blended Price (USD/1M Tokens) | Price per Unit of Intelligence (USD/1M tokens) |
|---|---|---|---|
| GPT-5 (high) | 69 | $3.44 | $0.0499 |
| GPT-5 (medium) | 68 | $3.44 | $0.0506 |
| Grok 4 | 68 | $6.00 | $0.0882 |
| o3-pro | 68 | $35.00 | $0.5147 |
| o3 | 67 | $3.50 | $0.0522 |
| o4-mini (high) | 65 | $1.93 | $0.0297 |
| Gemini 2.5 Pro | 65 | $3.44 | $0.0529 |
| GPT-5 mini | 64 | $0.69 | $0.0108 |
| Qwen3 235B 2507 (Reasoning) | 64 | $2.63 | $0.0411 |
| GPT-5 (low) | 63 | $3.44 | $0.0546 |
| gpt-oss-120B (high) | 61 | $0.26 | $0.0043 |
| Claude 4.1 Opus Thinking | 61 | $30.00 | $0.4918 |
| Claude 4 Sonnet Thinking | 59 | $6.00 | $0.1017 |
| DeepSeek R1 0528 | 59 | $0.96 | $0.0163 |
| Gemini 2.5 Flash (Reasoning) | 58 | $0.85 | $0.0147 |
| Grok 3 mini Reasoning (high) | 58 | $0.35 | $0.0060 |
| GLM-4.5 | 56 | $0.96 | $0.0171 |
| o3-mini (high) | 55 | $1.93 | $0.0351 |
| Claude 4 Opus Thinking | 55 | $30.00 | $0.5455 |
| GPT-5 nano | 54 | $0.14 | $0.0026 |
| Qwen3 30B 2507 (Reasoning) | 53 | $0.75 | $0.0142 |
| MiniMax M1 80k | 53 | $0.82 | $0.0155 |
| o3-mini | 53 | $1.93 | $0.0364 |
| Llama Nemotron Super 49B v1.5 (Reasoning) | 52 | $0.00 | $0.0000 |
| MiniMax M1 40k | 51 | $0.82 | $0.0161 |
| Qwen3 235B 2507 (Non-reasoning) | 51 | $1.23 | $0.0241 |
| EXAONE 4.0 32B (Reasoning) | 51 | $0.70 | $0.0137 |
| GLM-4.5-Air | 49 | $0.42 | $0.0086 |
| gpt-oss-20B (high) | 49 | $0.09 | $0.0018 |
| Claude 4.1 Opus | 49 | $30.00 | $0.6122 |
| Kimi K2 | 49 | $1.07 | $0.0218 |
| QwQ-32B | 48 | $0.49 | $0.0102 |
| Gemini 2.5 Flash | 47 | $0.85 | $0.0181 |
| GPT-4.1 | 47 | $3.50 | $0.0745 |
| Claude 4 Opus | 47 | $30.00 | $0.6383 |
| Llama Nemotron Ultra Reasoning | 46 | $0.90 | $0.0196 |
| Qwen3 30B 2507 (Non-reasoning) | 46 | $0.35 | $0.0076 |
| Claude 4 Sonnet | 46 | $6.00 | $0.1304 |
| Grok 3 Reasoning Beta | 46 | $0.00 | $0.0000 |
| Qwen3 Coder 480B | 45 | $3.00 | $0.0667 |
| Gemini 2.5 Flash-Lite (Reasoning) | 44 | $0.17 | $0.0039 |
| GPT-5 (minimal) | 44 | $3.44 | $0.0782 |
| Solar Pro 2 (Reasoning) | 43 | $0.50 | $0.0116 |
| GPT-4.1 mini | 42 | $0.70 | $0.0167 |
| Llama 4 Maverick | 42 | $0.39 | $0.0093 |
| DeepSeek R1 0528 Qwen3 8B | 42 | $0.07 | $0.0017 |
| Llama 3.3 Nemotron Super 49B Reasoning | 40 | $0.00 | $0.0000 |
| EXAONE 4.0 32B | 40 | $0.70 | $0.0175 |
| Grok 3 | 40 | $6.00 | $0.1500 |
| Mistral Medium 3 | 39 | $0.80 | $0.0205 |
| Magistral Medium | 38 | $2.75 | $0.0724 |
| Reka Flash 3 | 36 | $0.35 | $0.0097 |
| Magistral Small | 36 | $0.75 | $0.0208 |
| Nova Premier | 35 | $5.00 | $0.1429 |
| Gemini 2.5 Flash-Lite | 35 | $0.17 | $0.0049 |
| Llama 3.1 Nemotron Nano 4B v1.1 (Reasoning) | 34 | $0.00 | $0.0000 |
| Qwen3 Coder 30B | 33 | $0.90 | $0.0273 |
| Solar Pro 2 | 33 | $0.50 | $0.0152 |
| Llama 4 Scout | 33 | $0.20 | $0.0061 |
| Mistral Small 3.2 | 32 | $0.15 | $0.0047 |
| Command A | 32 | $4.38 | $0.1369 |
| Devstral Medium | 31 | $0.80 | $0.0258 |
| Llama 3.3 70B | 31 | $0.58 | $0.0187 |
| GPT-4.1 nano | 30 | $0.17 | $0.0057 |
| Llama 3.1 405B | 29 | $3.25 | $0.1121 |
| MiniMax-Text-01 | 29 | $0.42 | $0.0145 |
| GPT-4o (ChatGPT) | 29 | $7.50 | $0.2586 |
| Llama 3.3 Nemotron Super 49B v1 | 28 | $0.00 | $0.0000 |
| Phi-4 | 28 | $0.22 | $0.0079 |
| Llama Nemotron Super 49B v1.5 | 27 | $0.00 | $0.0000 |
| Llama 3.1 Nemotron 70B | 26 | $0.17 | $0.0065 |
| Gemma 3 27B | 25 | $0.00 | $0.0000 |
| GPT-4o mini | 24 | $0.26 | $0.0108 |
| Gemma 3 12B | 24 | $0.06 | $0.0025 |
| R1 1776 | 22 | $3.50 | $0.1591 |
| Llama 3.2 90B (Vision) | 22 | $0.54 | $0.0245 |
| Devstral Small | 21 | $0.15 | $0.0071 |
| Gemma 3n E4B | 18 | $0.03 | $0.0017 |
| DeepHermes 3 - Mistral 24B | 18 | $0.00 | $0.0000 |
| Jamba 1.7 Large | 18 | $3.50 | $0.1944 |
| Granite 3.3 8B | 18 | $0.09 | $0.0050 |
| Codestral (Jan '25) | 16 | $0.45 | $0.0281 |
| Phi-4 Multimodal | 15 | $0.00 | $0.0000 |
| Gemma 3 4B | 14 | $0.03 | $0.0021 |
| Llama 3.2 11B (Vision) | 13 | $0.10 | $0.0077 |
| Gemma 3n E2B | 10 | $0.00 | $0.0000 |
| Ministral 8B | 10 | $0.10 | $0.0100 |
| Aya Expanse 32B | 8 | $0.75 | $0.0938 |
| Ministral 3B | 8 | $0.04 | $0.0050 |
| Jamba 1.7 Mini | 6 | $0.25 | $0.0417 |
| DeepHermes 3 - Llama-3.1 8B | 4 | $0.00 | $0.0000 |
| Aya Expanse 8B | 4 | $0.75 | $0.1875 |
| Gemma 3 1B | 1 | $0.00 | $0.0000 |
Source: Artificial Analysis
You can immediately see the good options:
- GPT‑5‑mini: $0.01 per million tokens (OpenAI)
- gpt‑oss‑120B: $0.005 per million tokens (open source; multiple providers)
If you choose a proprietary model like GPT‑5‑mini, you can go to the provider’s website (platform.openai.com) and buy credits.
For gpt‑oss‑120B, you can use OpenRouter to see which providers offer it and their pricing:
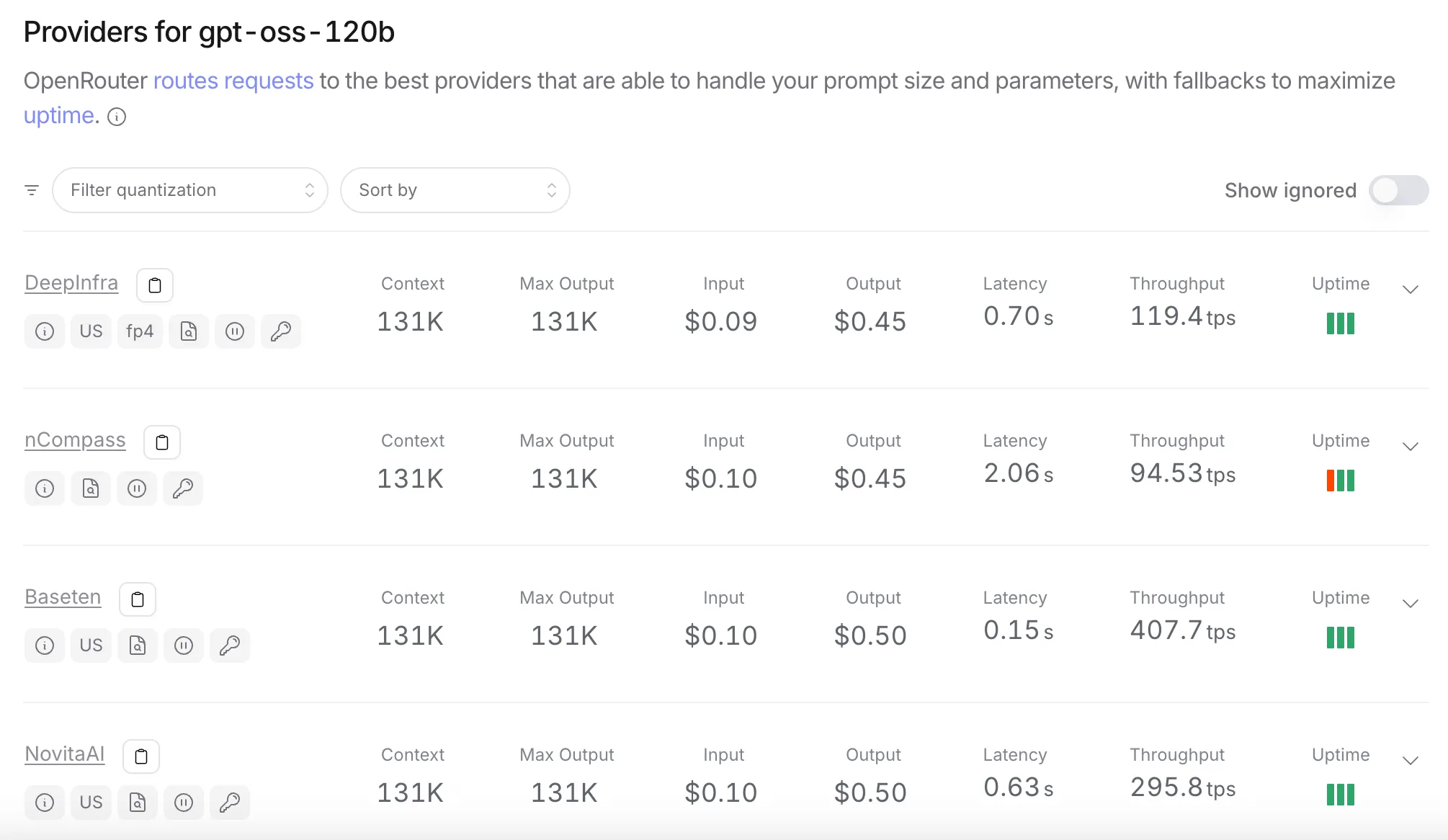
Source: openrouter.ai
If you don’t want to switch providers when they change prices, you can use OpenRouter directly to handle that for you. Most models follow the OpenAI JSON format, so you can use the OpenAI SDK and Agents SDK across providers—even for non‑OpenAI models.
OpenRouter takes a 5.5% markup on the credits you buy to pay for this broker service.
Other platforms like
also exist and offer additional features.
Running Open‑Source Models on Rented GPU Infrastructure
Well, this is the most disappointing option. I tried it with Modal. I deployed the smaller gpt‑oss‑20B model on an H200 GPU and, a few minutes later, I burned through my $5 starter credits. In comparison, I ran multiple heavy experiments over a full day with GPT‑5‑mini on the OpenAI platform and it cost me only 9 cents.
With Modal, by contrast, I did 12 small prompts to the model for $5.40 🤑:
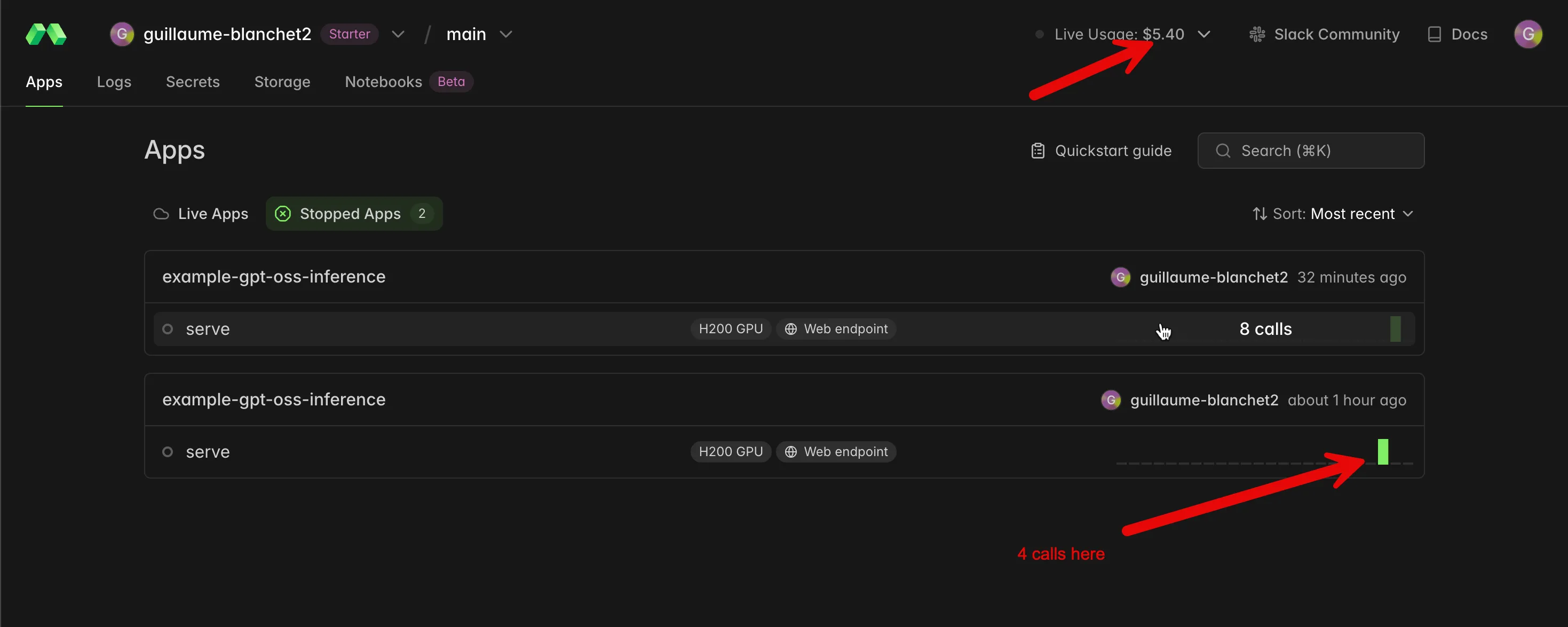
This is because Modal reserves your infrastructure until you explicitly stop it. But if you stop it right after a prompt, you’ll need to wait for the infrastructure to provision again before the next prompt. This is fast on Modal—thanks to significant R&D mitigating Docker and Kubernetes filesystem boot‑time overhead—but in my view it’s still too slow for production.
Conclusion
If you optimize purely for cost today, OpenAI wins. For proprietary models, GPT‑5‑mini is currently the cheapest at roughly $0.01 per million tokens. For open‑source models, the lowest prices (e.g., gpt‑oss‑120B around $0.005 per million tokens) are easily accessed through the OpenAI‑compatible ecosystem via gateways like OpenRouter, so you can standardize on the OpenAI SDK and still route to the cheapest providers.
Companies developing agentic workflows can lower their cost by using GPT-OSS-120B on a well equipped Mac Mini that could act an inference dev server in the local network too.
Note: prices and availability change frequently—always recheck before committing a stack.