From Developer to Manager: Leading an AI Coding Team
Why DRY matters more than ever with coding agents, why line-by-line code review doesn't scale, and how to replace both with metrics, architecture and pointed questions
A client question
A client asked me yesterday: “Since I started coding with agents, do I still need to centralize code? And do I still need to review every line?”
It’s a fair question. When an agent can rename a symbol across 400 files in 12 seconds, it’s tempting to conclude that duplication is now cheap and DRY can be relaxed. And reviewing every line the agent writes? That clearly doesn’t scale past the second pull request.
But I pushed back on the first half of that. DRY still matters, arguably more than before. Agents write faster, which means they also propagate the same design mistake faster: the same bug gets cloned in seven places before lunch, the same half-correct helper ends up duplicated across three modules. Loose duplication still breaks maintainability. The only thing that’s changed is how we enforce DRY: not by reading the diff, but by measuring it.
What Uncle Bob just admitted
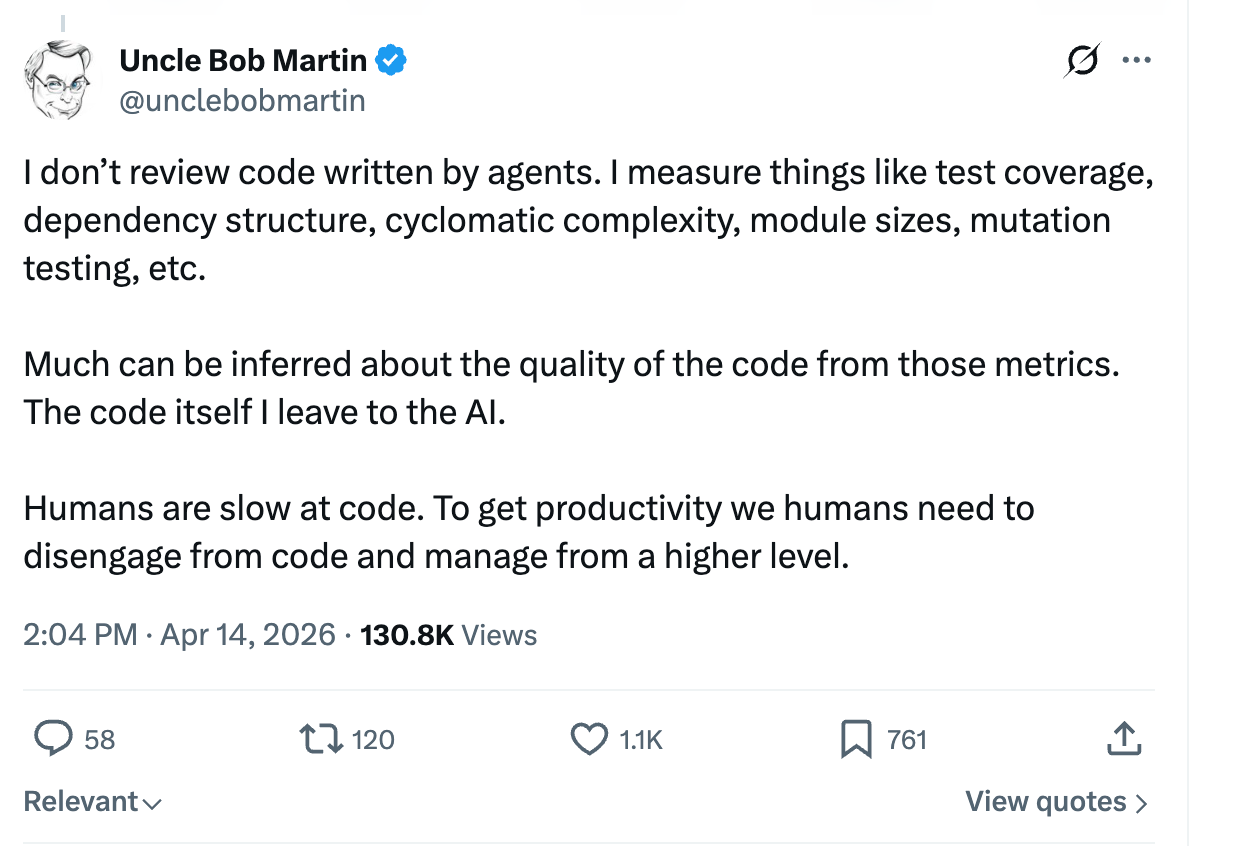
The timing was uncanny. The day before the client asked me this, Uncle Bob — the author of Clean Code, the guy who built his career on craftsmanship — had posted this on X:
“I don’t review code written by agents. I measure things like test coverage, dependency structure, cyclomatic complexity, module sizes, mutation testing, etc.
Much can be inferred about the quality of the code from those metrics. The code itself I leave to the AI.
Humans are slow at code. To get productivity we humans need to disengage from code and manage from a higher level.”
If the person who literally wrote the book on reviewing code is stepping back from reviewing code, something has shifted.
What I told the client
My answer was simple: since we’re no longer hands-on in the code — exactly what Uncle Bob is describing — we have to compensate with metrics. A lot of them.
- Measure, don’t read. Wire up SonarQube, or any equivalent. Require test coverage above 98%. Track cyclomatic complexity. Watch module sizes. Run mutation testing. The metrics catch what your eyes now skip over.
- Enforce DRY with a duplication metric. Exactly Uncle Bob’s point: don’t read for duplication, measure it. Sonar reports a duplicated-lines ratio, PMD/CPD flags copy-paste across files. Set a hard threshold in CI. Agents are fast enough to clone the same snippet across a dozen files before anyone notices, and each clone is a future bug that has to be fixed N times instead of once.
- Ask pointed questions. “Why is this class 400 lines? What breaks if I delete this layer? Where is the test that proves the edge case?” The agent answers honestly when confronted, but almost never volunteers the weakness.
- Own the architecture. The agent produces code. You own dependencies between modules, bounded contexts, the shape of the domain, what does and does not belong in this service. That is where human judgment still compounds.
Bonus analogy: you’re now managing an offshore team
Here is the mental model I keep coming back to — I didn’t share it with the client, but I think it sharpens the whole thing.
Working with a coding agent is like managing an offshore software team. The agent is fast, tireless, eager to please — and a little sycophantic. It will never tell you, unprompted, that the architecture it just produced is a mess. It will never push back on a requirement that doesn’t make sense. It will happily add a seventh layer of indirection because you vaguely asked for “flexibility.”
You don’t manage that kind of team by reading every commit. You manage it by asking the right questions, setting non-negotiable quality gates, and trusting the numbers more than the vibes. That’s exactly why the metrics above stop being “nice to have” and become the job itself.
The new loop
The day-to-day looks less like writing code and more like this:
- Define the change you want, in terms of behavior and architectural constraints.
- Let the agent produce the diff.
- Look at the metrics, not the diff — coverage, complexity, module boundaries, dependency graph.
- Where a metric degrades, ask the agent a pointed question and make it fix its own work.
- Repeat until the metrics are green and the architecture still makes sense.
You are slower at code than the agent will ever be. But the agent is slower than you will ever be at judgment. Spend your time where your edge is.
Conclusion
DRY still matters. Centralization still matters. Code review still matters. What changed is how we enforce them: not by reading every line, but by measuring. The craftsmanship hasn’t disappeared; it’s moved up a floor. We’ve gone from writing the code to running the team that writes it. The ones who thrive in the next few years are the ones who learn to manage well.