Le guide d'achat ultime des fournisseurs de LLM
Comment exécuter votre flux de travail agentique à moindre coût

Quel est le moyen le plus économique d’exécuter un Large Language Model (LLM) ?
Quand vous exploitez des LLM, vous devez prendre une décision clé : où les exécuter ? Les options se sont multipliées, chacune avec ses compromis. Devriez‑vous :
- Acheter du matériel dédié pour exécuter un LLM open source en local ?
- Utiliser un service cloud comme OpenAI ou Google Gemini, ou payer pour l’inférence sur une plateforme qui héberge des LLM open source comme Groq ou DeepInfra ?
- Louer de la puissance GPU brute chez un fournisseur cloud comme Modal pour héberger vous‑même un modèle open source ?
J’ai exploré ces trois pistes, voici mes conclusions.
Exécuter des LLM open source directement sur votre machine — ou pourquoi l’action Apple pourrait exploser
Si vous voulez exécuter un LLM en local, il faut d’abord choisir un modèle open source pertinent.
Vous voulez le modèle open source le plus « intelligent » possible avec les exigences matérielles les plus faibles.
Pour cela, consultez des classements comme :
Je préfère Artificial Analysis parce qu’il calcule un « indice d’intelligence », un composite de plusieurs benchmarks réputés pour chaque modèle.
À l’heure actuelle, le nouveau gpt-oss-120B semble être le moins cher à exécuter chez les fournisseurs cloud tout en conservant un bon score (61), le plaçant deuxième en intelligence. S’il est moins cher dans le cloud, il est probablement moins exigeant en calcul — et ce sera pareil sur votre matériel.
Or, gpt-oss-120B demande du matériel haut de gamme comme une NVIDIA A100 ou H100 avec 80 Go de VRAM (mémoire dédiée au GPU).
La partie intéressante, c’est que l’architecture d’Apple mélange VRAM et RAM, atténuant la dépendance au seul GPU.
La bastille économique secrète d’Apple : l’architecture mémoire unifiée (UMA)
Sur les PC traditionnels, le CPU a sa mémoire (RAM) et le GPU a la sienne (VRAM), plus rapide. Lorsqu’on exécute un LLM, il faut sans cesse copier des données entre ces deux mémoires séparées, créant un goulot d’étranglement qui ralentit tout.
Les puces Apple M, comme la M4 Max, adoptent une autre approche.
Mémoire partagée : avec l’UMA, le CPU, le GPU et le Neural Engine (NPU) partagent un seul grand pool de mémoire haute vitesse. Votre RAM locale est ce pool unifié.
Plus de copies massives : puisque tous les composants utilisent la même mémoire, pas besoin de dupliquer ou transférer d’énormes volumes de données. Le GPU peut accéder directement aux données de modèle utilisées par le CPU avec un délai minimal. Cela améliore drastiquement l’efficacité et la vitesse.
C’est pourquoi certains obtiennent des résultats décents (40 tokens/s) en exécutant gpt-oss-120B sur un M4 Max : https://www.reddit.com/r/LocalLLM/comments/1mix4yp/getting_40_tokenssec_with_latest_openai_120b/
À titre de comparaison, ChatGPT en ligne délivre environ 100 tokens/s. Cela dit, un MacBook Pro M4 Max avec 128 Go de RAM se vend actuellement 6 399 $ — pas donné — mais pour une entreprise qui exécute des LLM en local en ne payant que l’électricité, ça peut se défendre. Apple est peut‑être en retard dans la révolution LLM, mais possède le matériel pour la rendre scalable et abordable. En attendant que Wall Street s’en rende compte (ceci n’est pas un conseil financier).
J’ai testé GPT‑OSS‑20B sur mon MacBook Air M2 (24 Go)
Évidemment, mon MacBook Air ne pouvait pas faire tourner le plus grand modèle GPT‑OSS, mais j’ai exécuté la version 20B et obtenu ~20 tokens/s, ce qui est correct.
Si vous voulez essayer, voici la voie la plus simple :
- Téléchargez LM Studio depuis ici
- Ouvrez l’app et cliquez pour télécharger le modèle GPT‑OSS‑20B

- Cliquez sur le bouton « Start chat »
- Vous verrez l’interface de chat
- Posez une question. J’ai demandé « How to clean jewelry the right way? » et voici le débit de génération de tokens :
- Vous pouvez voir les statistiques de tokens par seconde en bas :

⚠️ Avertissement rapide
Petit rappel : LM Studio ou open‑webui sont intéressants pour jouer avec un modèle, mais ne remplacent pas une interface de chat comme ChatGPT, Claude ou Gemini. LM Studio et open‑webui n’offrent pas, prêts à l’emploi, les mêmes capacités agentiques (recherche Web, scraping, parsing de documents, etc.) que ces plateformes propriétaires, qui optimisent le comportement des modèles. Vous pouvez tenter de configurer ces capacités dans open‑webui, mais il est peu probable d’atteindre le même niveau de qualité et de performance que les plateformes en ligne.
Exécuter des LLM open source chez des fournisseurs d’inférence
Artificial Analysis peut vous aider à trouver les meilleurs fournisseurs d’inférence. L’idée consiste à trier les modèles par indice d’intelligence et à calculer le prix par point d’indice pour trouver le meilleur rapport qualité‑prix, puis à vérifier quels fournisseurs proposent ces modèles. J’ai fait le calcul et l’ai résumé dans le tableau ci‑dessous :
| Modèle | Indice d'intelligence Artificial Analysis | Prix mixte (USD/1M tokens) | Prix par unité d'intelligence (USD/1M tokens) |
|---|---|---|---|
| GPT-5 (high) | 69 | $3.44 | $0.0499 |
| GPT-5 (medium) | 68 | $3.44 | $0.0506 |
| Grok 4 | 68 | $6.00 | $0.0882 |
| o3-pro | 68 | $35.00 | $0.5147 |
| o3 | 67 | $3.50 | $0.0522 |
| o4-mini (high) | 65 | $1.93 | $0.0297 |
| Gemini 2.5 Pro | 65 | $3.44 | $0.0529 |
| GPT-5 mini | 64 | $0.69 | $0.0108 |
| Qwen3 235B 2507 (Reasoning) | 64 | $2.63 | $0.0411 |
| GPT-5 (low) | 63 | $3.44 | $0.0546 |
| gpt-oss-120B (high) | 61 | $0.26 | $0.0043 |
| Claude 4.1 Opus Thinking | 61 | $30.00 | $0.4918 |
| Claude 4 Sonnet Thinking | 59 | $6.00 | $0.1017 |
| DeepSeek R1 0528 | 59 | $0.96 | $0.0163 |
| Gemini 2.5 Flash (Reasoning) | 58 | $0.85 | $0.0147 |
| Grok 3 mini Reasoning (high) | 58 | $0.35 | $0.0060 |
| GLM-4.5 | 56 | $0.96 | $0.0171 |
| o3-mini (high) | 55 | $1.93 | $0.0351 |
| Claude 4 Opus Thinking | 55 | $30.00 | $0.5455 |
| GPT-5 nano | 54 | $0.14 | $0.0026 |
| Qwen3 30B 2507 (Reasoning) | 53 | $0.75 | $0.0142 |
| MiniMax M1 80k | 53 | $0.82 | $0.0155 |
| o3-mini | 53 | $1.93 | $0.0364 |
| Llama Nemotron Super 49B v1.5 (Reasoning) | 52 | $0.00 | $0.0000 |
| MiniMax M1 40k | 51 | $0.82 | $0.0161 |
| Qwen3 235B 2507 (Non-reasoning) | 51 | $1.23 | $0.0241 |
| EXAONE 4.0 32B (Reasoning) | 51 | $0.70 | $0.0137 |
| GLM-4.5-Air | 49 | $0.42 | $0.0086 |
| gpt-oss-20B (high) | 49 | $0.09 | $0.0018 |
| Claude 4.1 Opus | 49 | $30.00 | $0.6122 |
| Kimi K2 | 49 | $1.07 | $0.0218 |
| QwQ-32B | 48 | $0.49 | $0.0102 |
| Gemini 2.5 Flash | 47 | $0.85 | $0.0181 |
| GPT-4.1 | 47 | $3.50 | $0.0745 |
| Claude 4 Opus | 47 | $30.00 | $0.6383 |
| Llama Nemotron Ultra Reasoning | 46 | $0.90 | $0.0196 |
| Qwen3 30B 2507 (Non-reasoning) | 46 | $0.35 | $0.0076 |
| Claude 4 Sonnet | 46 | $6.00 | $0.1304 |
| Grok 3 Reasoning Beta | 46 | $0.00 | $0.0000 |
| Qwen3 Coder 480B | 45 | $3.00 | $0.0667 |
| Gemini 2.5 Flash-Lite (Reasoning) | 44 | $0.17 | $0.0039 |
| GPT-5 (minimal) | 44 | $3.44 | $0.0782 |
| Solar Pro 2 (Reasoning) | 43 | $0.50 | $0.0116 |
| GPT-4.1 mini | 42 | $0.70 | $0.0167 |
| Llama 4 Maverick | 42 | $0.39 | $0.0093 |
| DeepSeek R1 0528 Qwen3 8B | 42 | $0.07 | $0.0017 |
| Llama 3.3 Nemotron Super 49B Reasoning | 40 | $0.00 | $0.0000 |
| EXAONE 4.0 32B | 40 | $0.70 | $0.0175 |
| Grok 3 | 40 | $6.00 | $0.1500 |
| Mistral Medium 3 | 39 | $0.80 | $0.0205 |
| Magistral Medium | 38 | $2.75 | $0.0724 |
| Reka Flash 3 | 36 | $0.35 | $0.0097 |
| Magistral Small | 36 | $0.75 | $0.0208 |
| Nova Premier | 35 | $5.00 | $0.1429 |
| Gemini 2.5 Flash-Lite | 35 | $0.17 | $0.0049 |
| Llama 3.1 Nemotron Nano 4B v1.1 (Reasoning) | 34 | $0.00 | $0.0000 |
| Qwen3 Coder 30B | 33 | $0.90 | $0.0273 |
| Solar Pro 2 | 33 | $0.50 | $0.0152 |
| Llama 4 Scout | 33 | $0.20 | $0.0061 |
| Mistral Small 3.2 | 32 | $0.15 | $0.0047 |
| Command A | 32 | $4.38 | $0.1369 |
| Devstral Medium | 31 | $0.80 | $0.0258 |
| Llama 3.3 70B | 31 | $0.58 | $0.0187 |
| GPT-4.1 nano | 30 | $0.17 | $0.0057 |
| Llama 3.1 405B | 29 | $3.25 | $0.1121 |
| MiniMax-Text-01 | 29 | $0.42 | $0.0145 |
| GPT-4o (ChatGPT) | 29 | $7.50 | $0.2586 |
| Llama 3.3 Nemotron Super 49B v1 | 28 | $0.00 | $0.0000 |
| Phi-4 | 28 | $0.22 | $0.0079 |
| Llama Nemotron Super 49B v1.5 | 27 | $0.00 | $0.0000 |
| Llama 3.1 Nemotron 70B | 26 | $0.17 | $0.0065 |
| Gemma 3 27B | 25 | $0.00 | $0.0000 |
| GPT-4o mini | 24 | $0.26 | $0.0108 |
| Gemma 3 12B | 24 | $0.06 | $0.0025 |
| R1 1776 | 22 | $3.50 | $0.1591 |
| Llama 3.2 90B (Vision) | 22 | $0.54 | $0.0245 |
| Devstral Small | 21 | $0.15 | $0.0071 |
| Gemma 3n E4B | 18 | $0.03 | $0.0017 |
| DeepHermes 3 - Mistral 24B | 18 | $0.00 | $0.0000 |
| Jamba 1.7 Large | 18 | $3.50 | $0.1944 |
| Granite 3.3 8B | 18 | $0.09 | $0.0050 |
| Codestral (Jan '25) | 16 | $0.45 | $0.0281 |
| Phi-4 Multimodal | 15 | $0.00 | $0.0000 |
| Gemma 3 4B | 14 | $0.03 | $0.0021 |
| Llama 3.2 11B (Vision) | 13 | $0.10 | $0.0077 |
| Gemma 3n E2B | 10 | $0.00 | $0.0000 |
| Ministral 8B | 10 | $0.10 | $0.0100 |
| Aya Expanse 32B | 8 | $0.75 | $0.0938 |
| Ministral 3B | 8 | $0.04 | $0.0050 |
| Jamba 1.7 Mini | 6 | $0.25 | $0.0417 |
| DeepHermes 3 - Llama-3.1 8B | 4 | $0.00 | $0.0000 |
| Aya Expanse 8B | 4 | $0.75 | $0.1875 |
| Gemma 3 1B | 1 | $0.00 | $0.0000 |
Source : Artificial Analysis
On voit tout de suite de bonnes options :
- GPT‑5‑mini : 0,01 $ par million de tokens (OpenAI)
- gpt‑oss‑120B : 0,005 $ par million de tokens (open source ; multiples fournisseurs)
Si vous choisissez un modèle propriétaire comme GPT‑5‑mini, rendez‑vous sur le site du fournisseur (platform.openai.com) pour acheter des crédits.
Pour gpt‑oss‑120B, vous pouvez utiliser OpenRouter pour voir quels fournisseurs l’offrent et leurs prix :
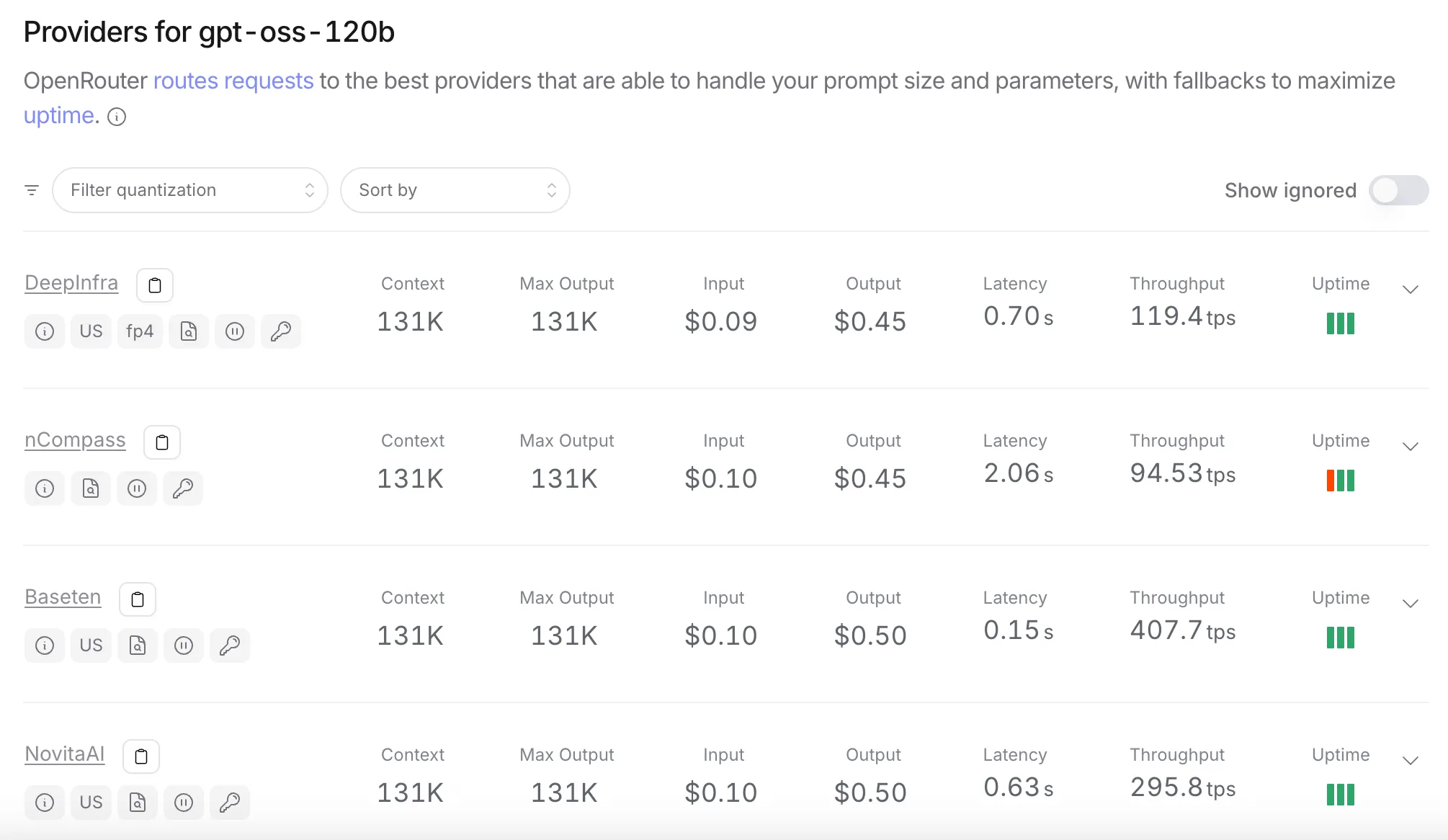
Source : openrouter.ai
Si vous ne voulez pas changer de fournisseur quand les prix bougent, vous pouvez utiliser OpenRouter directement pour gérer cela à votre place. La plupart des modèles suivent le format JSON d’OpenAI, donc vous pouvez utiliser le SDK OpenAI et son Agents SDK chez différents fournisseurs — même pour des modèles non‑OpenAI.
OpenRouter prend une marge de 5,5 % sur les crédits achetés pour financer ce service d’agrégation.
D’autres plateformes comme
existent aussi et offrent des fonctionnalités supplémentaires.
Exécuter des modèles open source sur une infrastructure GPU louée
Eh bien, c’est l’option la plus décevante. Je l’ai testée avec Modal. J’ai déployé le plus petit modèle gpt‑oss‑20B sur un GPU H200 et, quelques minutes plus tard, j’avais brûlé mes 5 $ de crédits de départ. À titre de comparaison, j’ai mené plusieurs expériences lourdes toute une journée avec GPT‑5‑mini sur la plateforme OpenAI et cela ne m’a coûté que 9 centimes.
Avec Modal, à l’inverse, j’ai fait 12 petites invites pour 5,40 $ 🤑 :
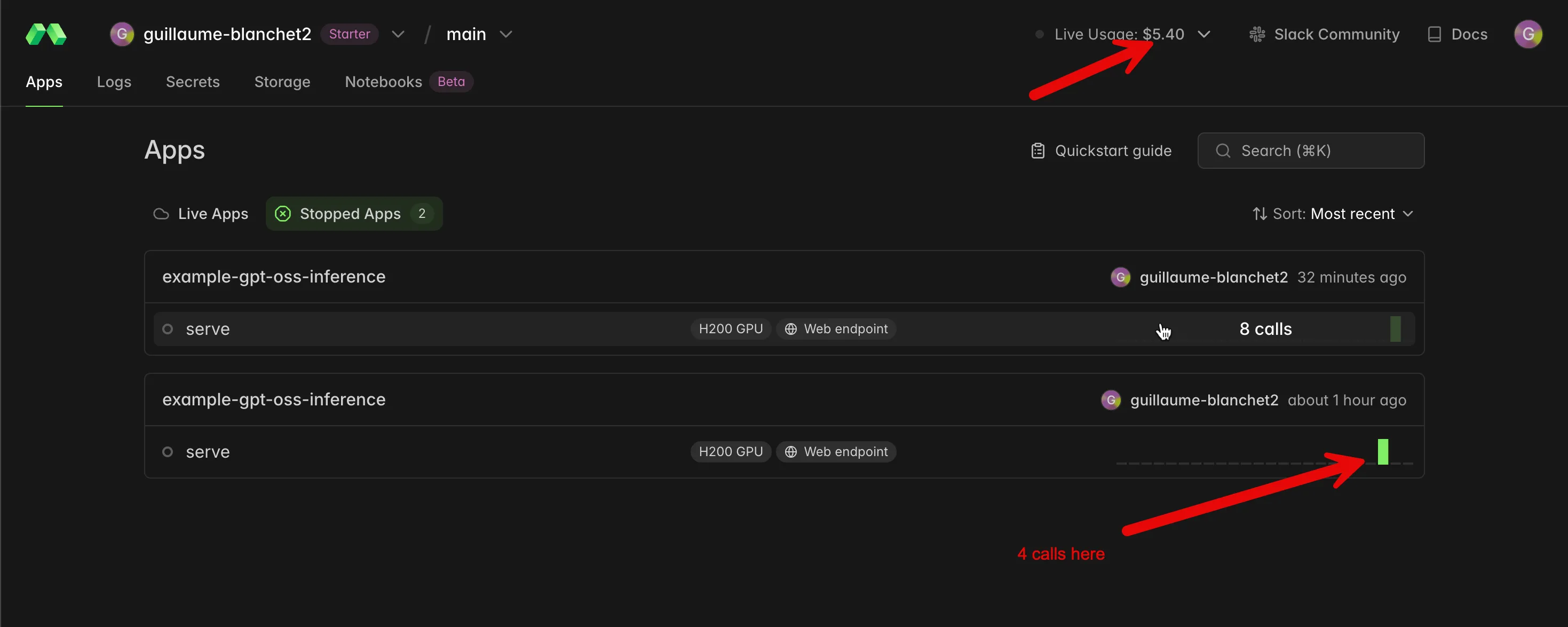
C’est parce que Modal réserve votre infrastructure jusqu’à ce que vous l’arrêtiez explicitement. Mais si vous l’arrêtez juste après une invite, il faudra attendre de nouveau l’approvisionnement de l’infrastructure avant la prochaine invite. C’est rapide chez Modal — grâce à de gros efforts R&D pour atténuer les surcoûts de démarrage Docker/Kubernetes — mais à mon avis ça reste trop lent pour la production.
Conclusion
Si vous optimisez uniquement le coût aujourd’hui, OpenAI gagne. Pour les modèles propriétaires, GPT‑5‑mini est actuellement le moins cher, autour de 0,01 $ par million de tokens. Pour les modèles open source, les prix les plus bas (par ex. gpt‑oss‑120B autour de 0,005 $ par million de tokens) sont facilement accessibles via l’écosystème compatible OpenAI grâce à des passerelles comme OpenRouter, ce qui vous permet d’utiliser le standard SDK d’OpenAI tout en routant vers les fournisseurs les moins chers.
Les entreprises qui développent des workflows agentiques peuvent réduire leurs coûts en utilisant GPT‑OSS‑120B sur un Mac mini bien équipé, qui peut aussi servir de serveur d’inférence de développement sur le réseau local.
Remarque : les prix et la disponibilité évoluent rapidement — revérifiez toujours avant d’arrêter une pile.