Votre système hérité n'est pas un passif, c'est une mine d'or : débloquez-le avec Salesforce
Comment synchroniser les données Salesforce vers votre système

Synchroniser les données Salesforce vers votre système
Introduction
Salesforce est l’un des systèmes CRM les plus puissants du marché. Cette plateforme “low-code” peut remplacer tout un département informatique en offrant un site web pour gérer vos clients, la facturation, les campagnes marketing, les interventions sur le terrain, et bien plus encore.
Même si elle peut gérer tout votre back office, elle ne peut pas remplacer votre image de marque ou certains systèmes au cœur de votre modèle d’affaires. L’intégration des données Salesforce est donc fondamentale pour présenter à vos clients des produits personnalisés tout en transférant leurs données vers le CRM pour assurer la cohérence entre vos systèmes.
Installer la CLI Salesforce (“sf”)
La première étape pour travailler efficacement avec les données Salesforce est d’installer “sf”.
Cet outil en ligne de commande vous permet de tester rapidement vos requêtes vers le CRM. Par exemple :
sf org login web
sf org list
sf data query --query "SELECT Id, Name, Account.Name FROM Contact" -o <ORG_USERNAME>Ces trois commandes vous permettent de vous connecter à votre instance Salesforce, voir les détails de votre organisation, et finalement utiliser ces détails pour exécuter une requête. Voici à quoi cela ressemble sur une instance de test développeur :
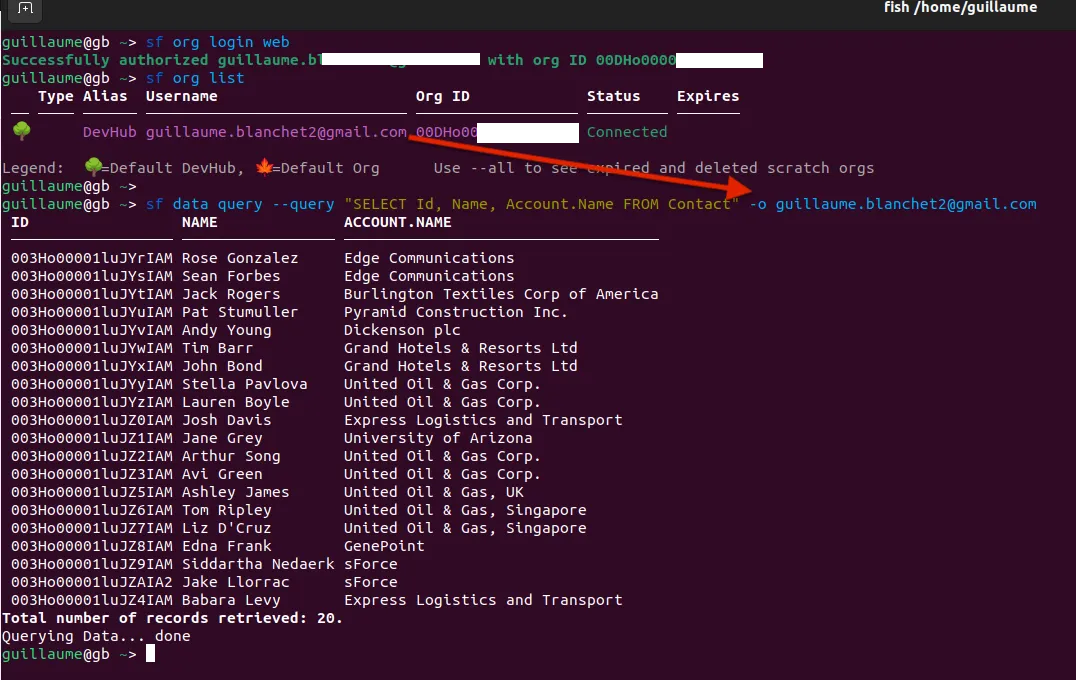
Comme vous pouvez le voir, Salesforce vous fait une faveur en créant l’instance avec des données pré-remplies.
Synchronisation programmatique utilisant l’API REST de Salesforce
Une fois que vous avez testé les requêtes que vous voulez utiliser dans votre programme de synchronisation avec sf, il ne reste plus qu’à écrire le code qui exécutera ces requêtes pour effectuer la synchronisation.
Bien sûr, contacter l’API REST directement nécessiterait de recoder les objets de transfert de données (DTO), ce que nous voulons éviter. Salesforce fournit un excellent wrapper Node.js (jsforce) pour son API, et c’est celui que je recommande pour plusieurs raisons :
- Salesforce recommande cet écosystème ;
sfa été codé avec Node.js ;- C’est l’un des deux seuls wrappers recommandés par la documentation du système ;
- jsforce est maintenu par Salesforce, contrairement à d’autres wrappers dans d’autres langages de programmation majeurs (par exemple : https://github.com/simple-salesforce/simple-salesforce) ;
- La documentation est supérieure aux autres wrappers, car il y a un site web dédié à la documentation jsforce.
Exemple de récupération de données avec Jsforce
Jsforce aura besoin d’un “jeton de sécurité” en plus de votre mot de passe pour se connecter à votre instance Salesforce. Naviguez vers “Setup” :
Puis créez un jeton de sécurité pour vous-même :
Voici un exemple de code qui récupère les contacts de la base de données Salesforce :
var jsforce = require('jsforce');
var username = '<email>';
var securityToken = '<security-token>';
var password = '<password>';
var conn = new jsforce.Connection({
loginUrl : 'https://guillaumeblanchet-dev-ed.develop.my.salesforce.com'
});
conn.login(username, password + securityToken, function(err, res) {
conn.query('SELECT Id, Name FROM Account', function(err, res) {
console.log(res);
});
});Vous devriez voir quelque chose comme ceci dans votre console :
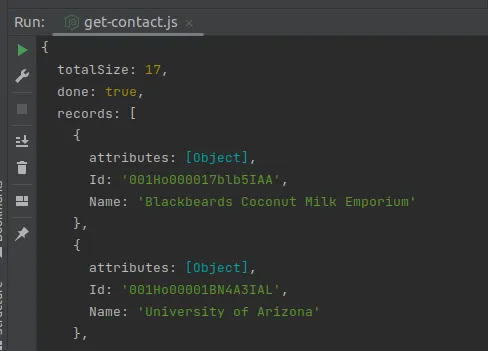
Comme vous pouvez le voir, l’API retourne des informations pour vous aider à paginer les requêtes. Puisque nous utilisons un wrapper de premier plan, Jsforce peut gérer la pagination lui-même avec l’événement record.
Exemple de synchronisation Firebase <-> Salesforce
Voici un exemple plus complet qui supprime d’abord la table synchronisée dans le système cible (ici, une base de données Firebase) puis insère les entrées Salesforce une par une :
conn.login(username, password + securityToken, (err, res) => {
// effacer votre table de comptes de base de données synchronisée (exemple avec firebase)
firebase.database().ref('account').remove();
var query = conn.query('SELECT Id, Name FROM Account')
.on('record', record => {
console.log(record);
// insérer l'enregistrement dans votre base de données (exemple avec firebase)
firebase.database().ref('account').push(record);
})
.on('end', () => {
console.log("total dans la base de données : " + query.totalSize);
console.log("total récupéré : " + query.totalFetched);
})
.run({ autoFetch : true });
});J’ai délibérément omis l’initialisation de la connexion Firebase pour me concentrer sur le code pertinent. Cependant, vous pouvez consulter la documentation pour Node.js ici : https://firebase.google.com/docs/reference/node.
Notez la fonctionnalité autoFetch, qui permet la pagination automatique des requêtes et démontre l’utilité de bien choisir votre wrapper avant d’intégrer avec Salesforce (ou tout autre système).
Exécution de la synchronisation périodique
Bien sûr, vous pourriez placer le petit script ci-dessus dans une fonction Azure, un AWS Lambda, ou même une fonction cloud directement dans Firebase pour l’exécuter à intervalles réguliers.
Personnellement, je préfère utiliser un job DevOps. L’idée est de continuer à bénéficier de plateformes puissantes qui en font plus pour nous. C’est le cas des plateformes DevOps comme Azure DevOps, GitLab, ou GitHub Actions. Ces plateformes ne vous limitent pas dans le nombre de langages de programmation supportés. Elles offrent une large gamme de systèmes d’exploitation pour exécuter votre code. Elles ont des interfaces extrêmement matures et centrales pour leur cœur de métier. Elles sont vraiment les meilleurs orchestrateurs cloud du marché, même si elles sont mieux connues pour effectuer des tâches de compilation et de déploiement.
Par exemple, voici un job GitHub Action qui synchronise vos données à minuit tous les jours (voir la documentation pour tous les types d’horaires supportés : GitHub Docs) :
name: Node.js CI
on:
schedule:
- cron: '0 0 * * *' # Exécuter tous les jours à minuit UTC
jobs:
build:
runs-on: ubuntu-latest
defaults:
run:
working-directory: ./Salesforce
strategy:
matrix:
node-version: [14.x, 16.x, 18.x]
# Voir le calendrier de publication Node.js supporté sur https://nodejs.org/en/about/releases/
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
cache-dependency-path: ./Salesforce/package-lock.json
- run: npm ci
- shell: bash
env:
SF_PWD: ${{ secrets.SF_PWD }}
SF_SECURITY_TOKEN: ${{ secrets.SF_SECURITY_TOKEN }}
TEST: 'ça marche !!'
run: |
node get-contact.jsGitHub fournit un accès à tous les logs de synchronisation faits à minuit, et vous avez la possibilité de redéclencher les jobs échoués et de les gérer :
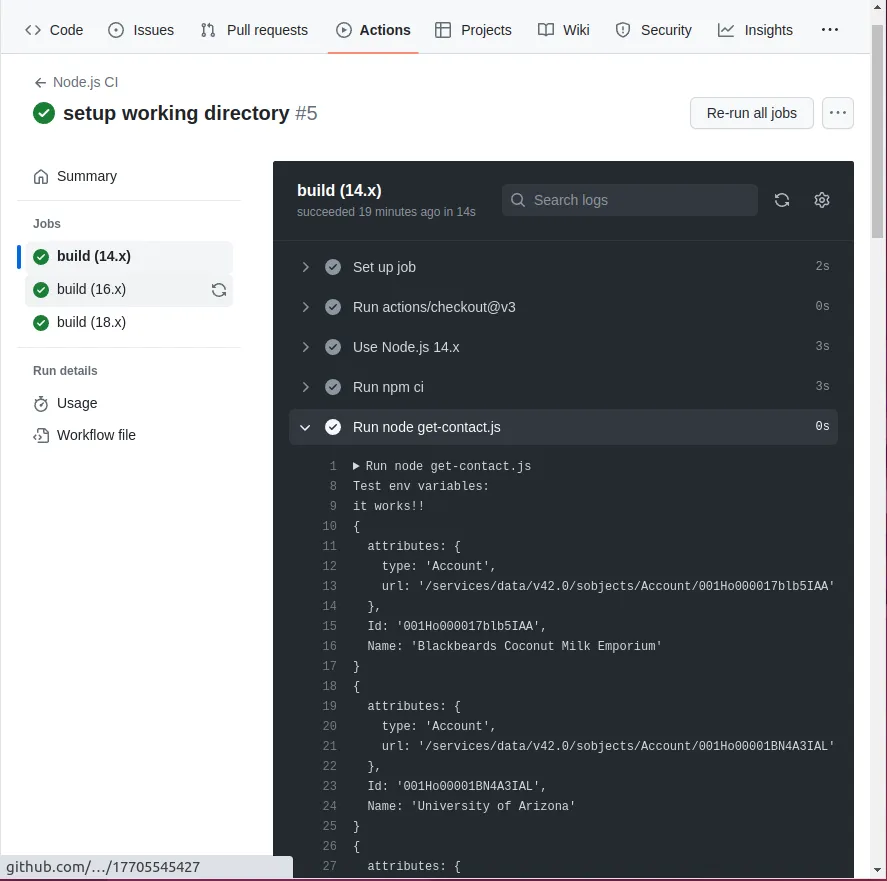
Les plateformes DevOps vous fournissent aussi des intégrations OpenID Connect (OIDC) pour éviter de gérer les secrets (ici, votre mot de passe et le jeton de sécurité), ce que les fonctions cloud n’offrent pas.
Les plateformes DevOps vous aideront aussi à identifier les problèmes de synchronisation en associant les nouveaux jobs échoués avec le code défaillant récemment commité. GitHub offrira même bientôt des assistants intelligents (bots) pour vous soutenir dans ce débogage.
Vous pouvez aussi gérer les accès et permissions pour les pipelines très précisément.
Conclusion
Vous avez maintenant les outils pour synchroniser vos données Salesforce avec votre système :
- Vous avez appris à utiliser la CLI Salesforce pour tester vos requêtes ;
- Vous avez appris à utiliser le wrapper Jsforce pour programmer votre synchronisation ;
- Vous avez appris à utiliser les plateformes DevOps pour orchestrer votre synchronisation.
Si la charge devient trop élevée pendant vos synchronisations, vous pouvez revenir à la pagination personnalisée pour charger des lots de données dans votre base de données avec une stratégie “bulk insert”. Pour Firebase, cela pourrait ressembler à ceci :
firebase.database().ref('account').set(records);Ceci est équivalent à remplacer toute la table de données de contact d’un coup pour un lot initial de records comme paramètre.
Notez que nous n’avons parlé que de synchronisation vers votre système et non vers Salesforce. Si vous voulez pousser de nouvelles données vers Salesforce, vous pouvez utiliser le même wrapper, car Jsforce offre une fonctionnalité “bulk insert” pour pousser efficacement plusieurs entrées pour de gros systèmes : Documentation Jsforce.